LinkBuffer in Jetpack Compose: From GapBuffer to Linked Slots

The New LinkBuffer SlotTable: What Changes and Why It Matters
The SlotTable is the internal data structure that stores Compose's entire composition hierarchy: every group, every remembered value, every composable's identity. Since Compose's first release, the SlotTable used a gap buffer to manage this data. The gap buffer, borrowed from text editors, works well for sequential insertions but pays an increasing cost for deletions, moves, and reordering as the composition grows. The new experimental LinkBuffer SlotTable replaces the gap buffer with a linked list structure that eliminates array copying for structural operations, making list reordering over twice as fast and most other operations roughly 10% faster.
In this article, you'll explore why the gap buffer becomes expensive for dynamic UIs, how the LinkBuffer's linked list architecture avoids these costs, the real world scenarios where the performance difference is most visible, how to enable the new implementation in your app, and the trade offs to consider. For a detailed walkthrough of the gap buffer's internal data model (groups, slots, anchors, the reader/writer pattern), see A Study of the Jetpack Compose SlotTable Internals. For a line by line comparison of the gap buffer and link buffer source code, see
From Gap Buffer to Linked List: How Compose Rewrote Its SlotTable for Faster Recomposition.
The fundamental problem: Array copies that scale with composition size
Every composable function in your app corresponds to a group in the SlotTable. When Compose recomposes, it reads and writes groups to track what changed. The data structure managing these groups directly affects how fast recomposition runs.
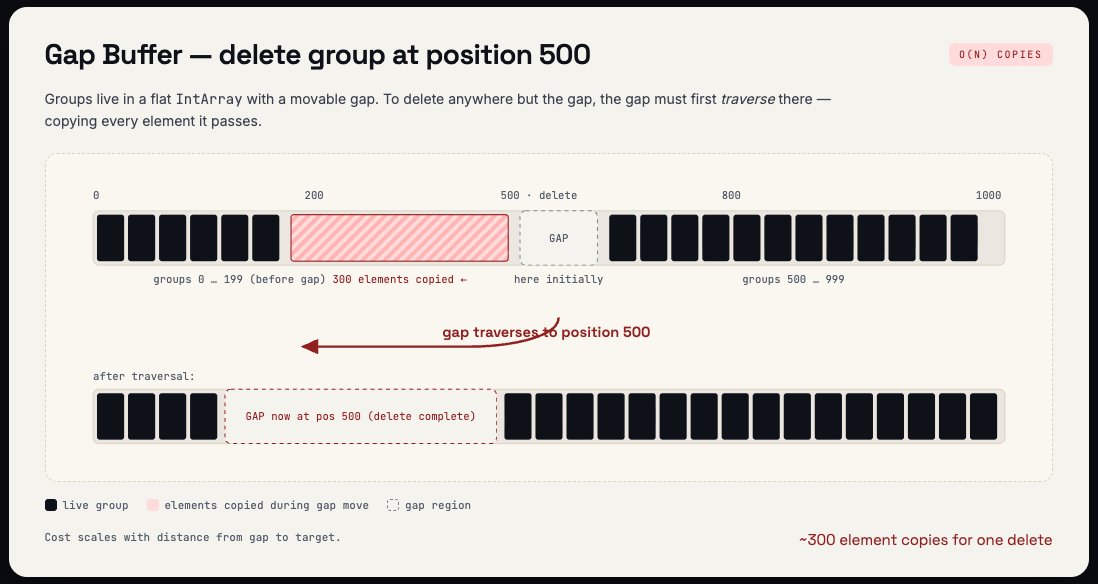
The gap buffer stores groups in a flat IntArray with an empty region (the gap) that moves to wherever the next write happens. Sequential insertions at the gap position are efficient. But when you delete a group elsewhere, or reorder groups, the gap must move to that position first, and moving the gap copies every element between its current position and the target.
For a composition with 1000 groups where you delete group 500, the gap must traverse 500 positions, copying elements along the way. Reordering an item in a list of 100 entries requires two gap movements (one to extract, one to re-insert), each copying a portion of the array. As compositions grow, these copies become the dominant cost of structural changes during recomposition.
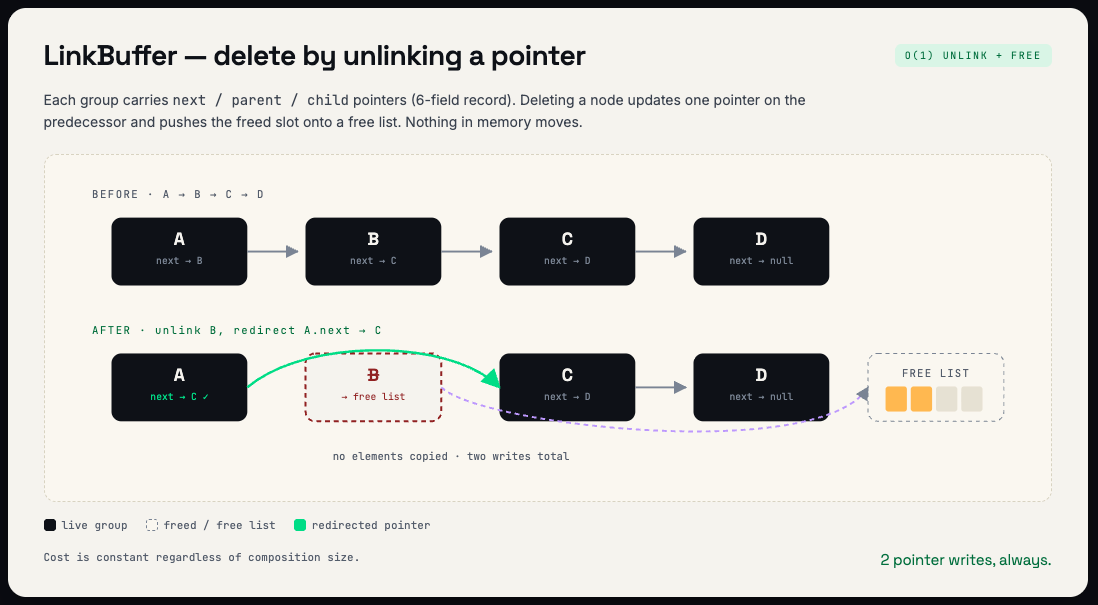
The LinkBuffer: Pointers instead of positions
The LinkBuffer replaces the flat array layout with a linked list structure. Groups are still stored in an IntArray for memory efficiency, but each group is now a 6 field record connected to its siblings, parent, and children through explicit pointer fields:
internal const val SLOT_TABLE_GROUP_SIZE = 6
private const val SLOT_TABLE_GROUP_KEY_OFFSET = 0 // composable identity
private const val SLOT_TABLE_GROUP_NEXT_OFFSET = 1 // next sibling
private const val SLOT_TABLE_GROUP_PARENT_OFFSET = 2 // parent group
private const val SLOT_TABLE_GROUP_CHILD_OFFSET = 3 // first child
private const val SLOT_TABLE_GROUP_FLAGS_OFFSET = 4 // group properties
private const val SLOT_TABLE_GROUP_SLOTS_OFFSET = 5 // slot data range
Each group points to its next sibling, its parent, and its first child. This means the composition tree is traversed by following pointers rather than calculating array offsets relative to a gap.
The key advantage: structural operations become pointer updates instead of array copies.
Deleting a group means unlinking it from the sibling chain (updating the predecessor's next pointer to skip the deleted node) and adding the freed slot to a free list for reuse. No elements move in memory.
Moving a group (reordering) means unlinking from the old position and linking into the new position. Two pointer updates, regardless of how far apart the positions are or how large the composition is.

Inserting a group allocates from the free list (or extends the array if needed) and links the new node into the chain.
Slot storage: Bump allocation with compaction
The gap buffer also managed slot data (the actual values stored per group, like remember results) using a second gap buffer. The LinkBuffer replaces this with bump allocation: new slots are appended sequentially at the end of the slots array. Each group stores a SlotRange encoded as a single integer with 4 bits for size and 28 bits for the starting address. Most composable groups have fewer than 15 slots, so the inline encoding covers the common case without any auxiliary lookup.
When the slots array fills up, the allocator runs a compaction pass: it scans all live groups, copies their slot data to the front contiguously, and updates the slot ranges. This is the only operation that copies slot data, and it happens only when the array is full. Between compactions, allocation is a single pointer increment. The allocator also reserves a small buffer (8 extra slots) after each moved range during compaction, allowing groups to grow without triggering another compaction immediately.
Where the performance difference matters most
Not all compositions benefit equally from the LinkBuffer. The gains are concentrated in scenarios that trigger frequent structural changes.
List reordering
When items in a Column or Row are reordered (e.g., via drag and drop or a sort change), the gap buffer must move groups to their new positions, copying elements for each move. Reordering N items involves N gap movements, each proportional to the distance moved. The LinkBuffer reorders by relinking pointers, making each move O(1). For lists with hundreds of items, this is where the "over twice as fast" benchmark result comes from.
Conditional content
if/when blocks that add or remove composable content cause insertions and deletions in the SlotTable. In the gap buffer, inserting at a position far from the current gap requires a full gap traversal. The LinkBuffer handles these as constant time link/unlink operations regardless of where in the tree the change occurs.
MovableContent
movableContentOf moves composable content from one location in the tree to another while preserving its state. In the gap buffer, this requires extracting the group from one position (gap movement + copy) and inserting it at another (second gap movement + copy). The LinkBuffer unlinks the subtree and relinks it at the new location without copying any data.
LazyColumn and SubcomposeLayout
LazyColumn uses SubcomposeLayout to compose items on demand during the layout phase. As items scroll in and out, groups are added and removed from the SlotTable. The gap buffer handles these additions efficiently when they happen at the gap position (which SubcomposeLayout generally arranges), so the improvement for steady state scrolling is closer to the 10% general improvement rather than the 2x improvement seen with reordering. However, operations like scrollToItem that jump to a distant position benefit more because they cause structural changes away from the gap.
Memory trade off
The linked list structure uses 6 fields per group instead of the gap buffer's 5, a 20% increase in per group memory. The free list adds a small overhead for tracking freed groups. In practice, this is offset by the elimination of the second gap buffer for slots and the reduced temporary memory needed during structural changes (no intermediate copies). For most apps, the memory difference is negligible compared to the performance gains.
What the release notes say
The Compose Runtime 1.10+ release notes describe the new SlotTable as follows: the rewrite is focused on improving recomposition performance by using substantially fewer memory copy operations than the gap buffer. Certain changes to the composition hierarchy, like reordering a long list of items, can recompose over twice as fast. Most other operations are on the order of 10% faster. The SlotTable implementation affects all composable methods and requires no recompilation. Using the new SlotTable is an app wide change, including for dependencies.

The implementation is still experimental and currently disabled by default. It can be enabled by setting ComposeRuntimeFlags.isLinkBufferComposerEnabled to true. In release builds with minification enabled, this value is assumed to be false in the default proguard-rules.pro file supplied with the runtime. To enable the new SlotTable in production, this assumption needs to be changed to true in the application's ProGuard rules file.
Two points in the release notes deserve emphasis. First, "requires no recompilation" means this is a pure runtime change. You do not need to update the Compose compiler plugin or rebuild your composables. The same compiled bytecode works with either SlotTable implementation. Second, "app wide change, including for dependencies" means every library composable in your dependency tree also runs on the new SlotTable. There is no way to enable it for your code but not for a library, or vice versa. This is by design: the SlotTable is a single shared data structure for the entire composition.
Enabling the LinkBuffer
The LinkBuffer is experimental and disabled by default. To enable it, set the feature flag before the first call to setContent():
ComposeRuntimeFlags.isLinkBufferComposerEnabled = true
This is an app wide change that applies to all composables, including those from dependencies. The runtime does not support mixing both implementations simultaneously.
For release builds with R8, the flag must be configured via ProGuard rules. The Compose runtime ships with a default rule that assumes the flag is false, so R8 strips the LinkBuffer code entirely. To keep it, add this to your app's ProGuard rules:
-assumevalues public class androidx.compose.runtime.ComposeRuntimeFlags {
static boolean isLinkBufferComposerEnabled return true;
}
Leaving both implementations in a release build without this rule prevents R8 from devirtualizing calls in the Compose runtime. This causes measurable performance degradation because the JIT cannot inline virtual method calls. Always configure the ProGuard rule to match the flag value so R8 can strip the unused implementation.
Gap buffer vs LinkBuffer: Operation complexity
| Operation | Gap Buffer | LinkBuffer |
|---|---|---|
| Sequential insert | O(1) amortized | O(1) |
| Insert at arbitrary position | O(N) gap movement | O(1) pointer link |
| Delete | O(N) gap movement | O(1) unlink + free |
| Move / Reorder | O(N) x 2 gap movements | O(1) x 2 pointer updates |
| Read / Traverse | O(1) per group | O(1) per group |
| Reorder N items | O(N x M) where M = avg distance | O(N) |
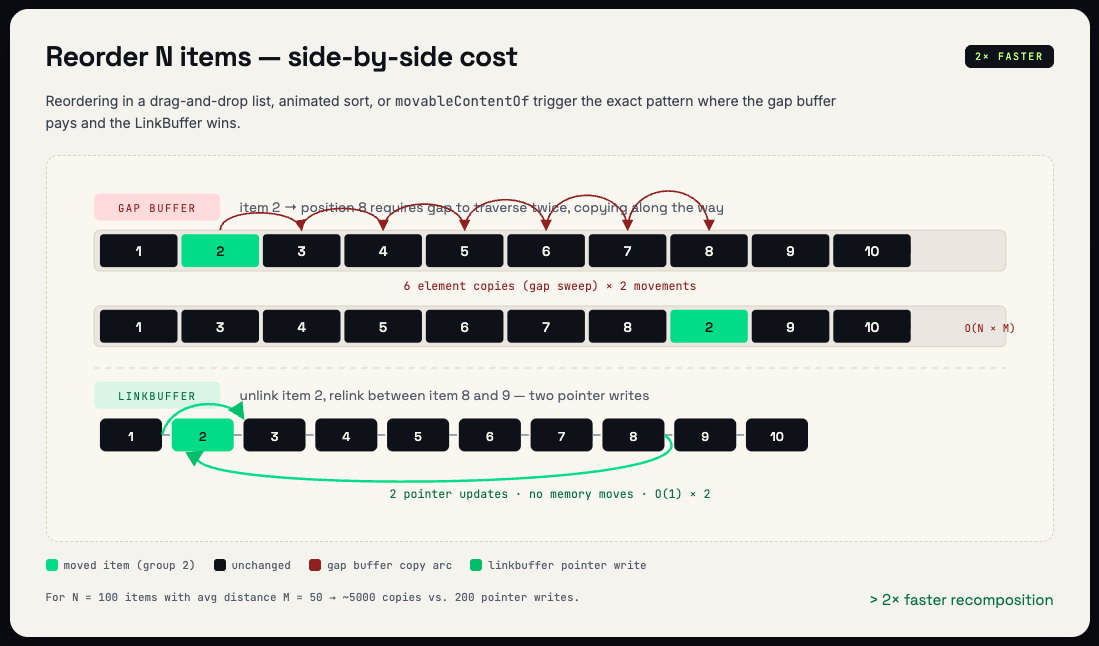
The table shows why the performance gap widens with composition size. For small, static UIs, both implementations perform similarly. For large, dynamic UIs with frequent structural changes, the LinkBuffer's constant time operations compound into significant savings.
Code organization
The architectural change is reflected in code structure. The gap buffer implementation is a single monolithic 4,243 line file. The LinkBuffer decomposes the same functionality into five focused files:
- SlotTable (1,268 lines): public API and table lifecycle
- SlotTableAddressSpace: group and slot storage, bump allocation, free list management
- SlotTableEditor: structural edit operations (insert, delete, move)
- SlotTableBuilder: building subtables for movable content
- SlotTableReader: read only traversal during recomposition
For a detailed walkthrough of each file and the algorithms they implement, see From Gap Buffer to Linked List.
Conclusion
In this article, you've explored the new LinkBuffer SlotTable and what it changes about Compose's internal composition tracking. The gap buffer's array copying cost, which scales linearly with composition size, is replaced by constant time pointer operations for deletions, moves, and reordering. Slot storage shifts from a second gap buffer to bump allocation with periodic compaction. The result is over 2x faster recomposition for list reordering scenarios and approximately 10% faster performance for general operations.
The practical impact depends on your app's UI patterns. Apps with static layouts see modest gains from the general 10% improvement. Apps with drag and drop lists, animated reordering, conditional content changes, or movableContentOf usage see the largest improvements because these patterns trigger the structural operations where the LinkBuffer excels.
Enabling the LinkBuffer is a single flag change with a matching ProGuard rule, and it requires no recompilation. For apps experiencing recomposition bottlenecks in dynamic UIs, it is one of the highest impact optimizations available today, a runtime change that speeds up every composable in your app without touching a single line of your code.
As always, happy coding!
— Jaewoong (skydoves)